AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]
Por um escritor misterioso
Last updated 20 janeiro 2025
![AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]](https://dfzljdn9uc3pi.cloudfront.net/2022/cs-1123/1/fig-10-full.png)
Artificial intelligence (AI) has achieved superhuman performance in board games such as Go, chess, and Othello (Reversi). In other words, the AI system surpasses the level of a strong human expert player in such games. In this context, it is difficult for a human player to enjoy playing the games with the AI. To keep human players entertained and immersed in a game, the AI is required to dynamically balance its skill with that of the human player. To address this issue, we propose AlphaDDA, an AlphaZero-based AI with dynamic difficulty adjustment (DDA). AlphaDDA consists of a deep neural network (DNN) and a Monte Carlo tree search, as in AlphaZero. AlphaDDA learns and plays a game the same way as AlphaZero, but can change its skills. AlphaDDA estimates the value of the game state from only the board state using the DNN. AlphaDDA changes a parameter dominantly controlling its skills according to the estimated value. Consequently, AlphaDDA adjusts its skills according to a game state. AlphaDDA can adjust its skill using only the state of a game without any prior knowledge regarding an opponent. In this study, AlphaDDA plays Connect4, Othello, and 6x6 Othello with other AI agents. Other AI agents are AlphaZero, Monte Carlo tree search, the minimax algorithm, and a random player. This study shows that AlphaDDA can balance its skill with that of the other AI agents, except for a random player. AlphaDDA can weaken itself according to the estimated value. However, AlphaDDA beats the random player because AlphaDDA is stronger than a random player even if AlphaDDA weakens itself to the limit. The DDA ability of AlphaDDA is based on an accurate estimation of the value from the state of a game. We believe that the AlphaDDA approach for DDA can be used for any game AI system if the DNN can accurately estimate the value of the game state and we know a parameter controlling the skills of the AI system.
![AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]](https://dfzljdn9uc3pi.cloudfront.net/2022/cs-1123/1/fig-3-full.png)
AlphaDDA: strategies for adjusting the playing strength of a fully
![AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]](https://miro.medium.com/v2/resize:fit:1400/1*s1JyknTBipuYaeK232bm1A.png)
Lessons From Alpha Zero (part 6) — Hyperparameter Tuning
![AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]](https://www.researchgate.net/publication/332466679/figure/fig1/AS:873418069127168@1585250503503/Bandits-and-the-Harlow-Task-A-Example-behavior-of-meta-reinforcement-learning-on.png)
Bandits and the Harlow Task. (A) Example behavior of meta
![AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]](http://spikingneuron.net/ja/img/quantize.png)
研究概要
![AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]](https://miro.medium.com/v2/resize:fit:1358/1*yzPRrbo45BwX9N4iq6S_ew.png)
Lessons from AlphaZero (part 3): Parameter Tweaking
![AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]](https://images-na.ssl-images-amazon.com/images/I/61DPdWpB4yL._AC_UL600_SR600,600_.jpg)
ALPHA GRIPZ Original Hand Grip Extensor Trainer
![AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]](https://dfzljdn9uc3pi.cloudfront.net/2022/cs-1123/1/fig-7-2x.jpg)
AlphaDDA: strategies for adjusting the playing strength of a fully
![AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]](https://imgopt.infoq.com/fit-in/1200x2400/filters:quality(80)/filters:no_upscale()/articles/multi-armed-bandits-reinforcement-learning/en/resources/7image4-1588077752247.jpg)
Reinforcement Machine Learning for Effective Clinical Trials
![AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]](https://media.springernature.com/lw685/springer-static/image/chp%3A10.1007%2F978-3-031-47546-7_16/MediaObjects/549401_1_En_16_Fig1_HTML.png)
Mastering the Card Game of Jaipur Through Zero-Knowledge Self-Play
![AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]](https://i1.rgstatic.net/publication/328489831_Horizontal_Scaling_With_A_Framework_For_Providing_AI_Solutions_Within_A_Game_Company/links/5bd0a02b299bf14eac81e249/largepreview.png)
PDF) Horizontal Scaling With A Framework For Providing AI
![AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]](https://www.researchgate.net/profile/Timothy_Lillicrap/publication/320473480/figure/fig1/AS:679322838904838@1538974594482/Self-play-reinforcement-learning-in-AlphaGo-Zero-a-The-program-plays-a-game-s-1-s_Q320.jpg)
Self-play reinforcement learning in AlphaGo Zero. a The program
![AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]](https://miro.medium.com/v2/resize:fit:640/1*j_f2mRcrE05RNwNoK6uHtw.png)
Lessons from AlphaZero (part 3): Parameter Tweaking
![AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]](https://media.springernature.com/lw685/springer-static/image/chp%3A10.1007%2F978-3-031-47546-7_16/MediaObjects/549401_1_En_16_Fig2_HTML.png)
Mastering the Card Game of Jaipur Through Zero-Knowledge Self-Play
![AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]](https://dfzljdn9uc3pi.cloudfront.net/2022/cs-1123/1/fig-1-full.png)
AlphaDDA: strategies for adjusting the playing strength of a fully
Recomendado para você
-
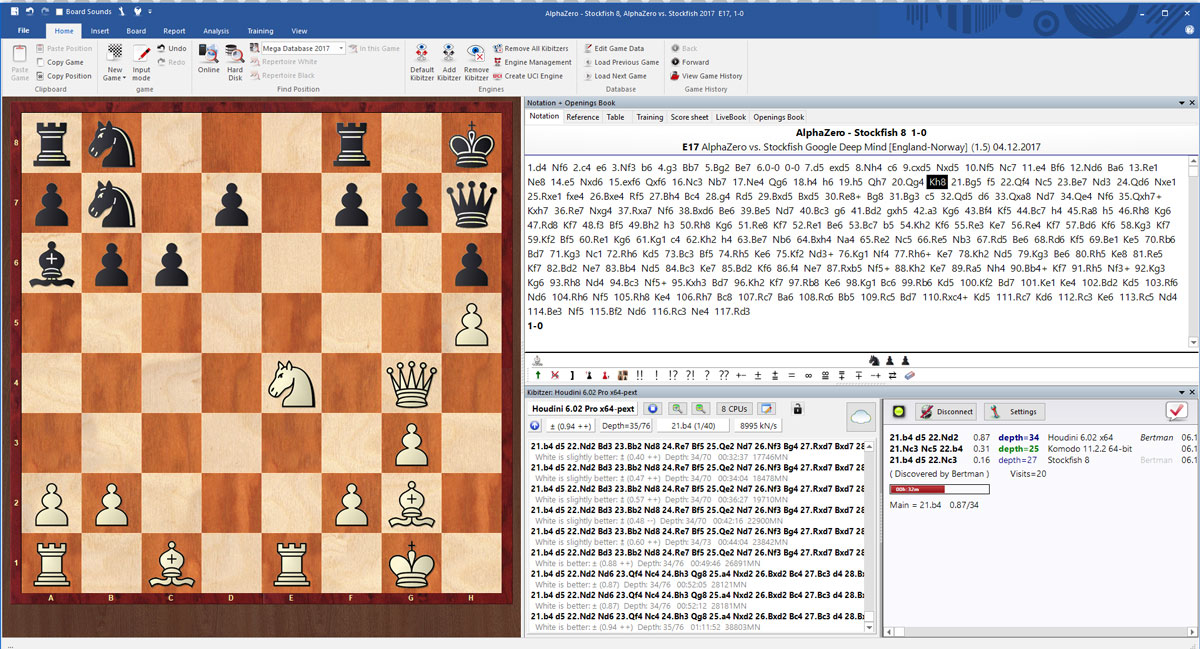 The future is here – AlphaZero learns chess20 janeiro 2025
The future is here – AlphaZero learns chess20 janeiro 2025 -
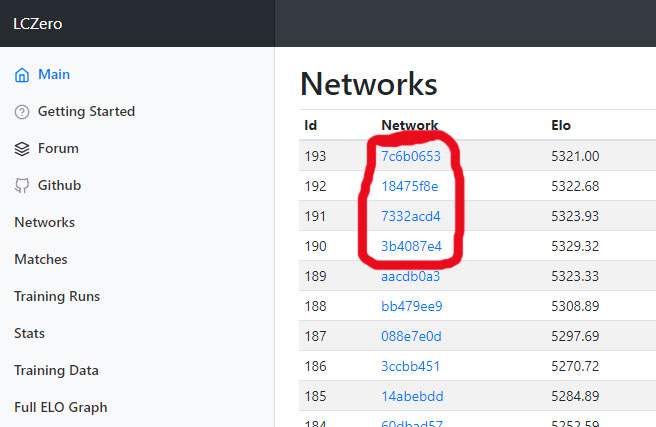 Leela Chess Zero: AlphaZero for the PC20 janeiro 2025
Leela Chess Zero: AlphaZero for the PC20 janeiro 2025 -
 ALPHA ZERO Songs MP3 Download, New Songs & Albums20 janeiro 2025
ALPHA ZERO Songs MP3 Download, New Songs & Albums20 janeiro 2025 -
Funkoi Games - Alpha Zero third campaign is available nowDownload it, upgrade it and have fun.20 janeiro 2025
-
 Street Fighter Alpha: Warriors' Dreams (a.k.a. Street Fighter Zero) Download (1998 Arcade action Game)20 janeiro 2025
Street Fighter Alpha: Warriors' Dreams (a.k.a. Street Fighter Zero) Download (1998 Arcade action Game)20 janeiro 2025 -
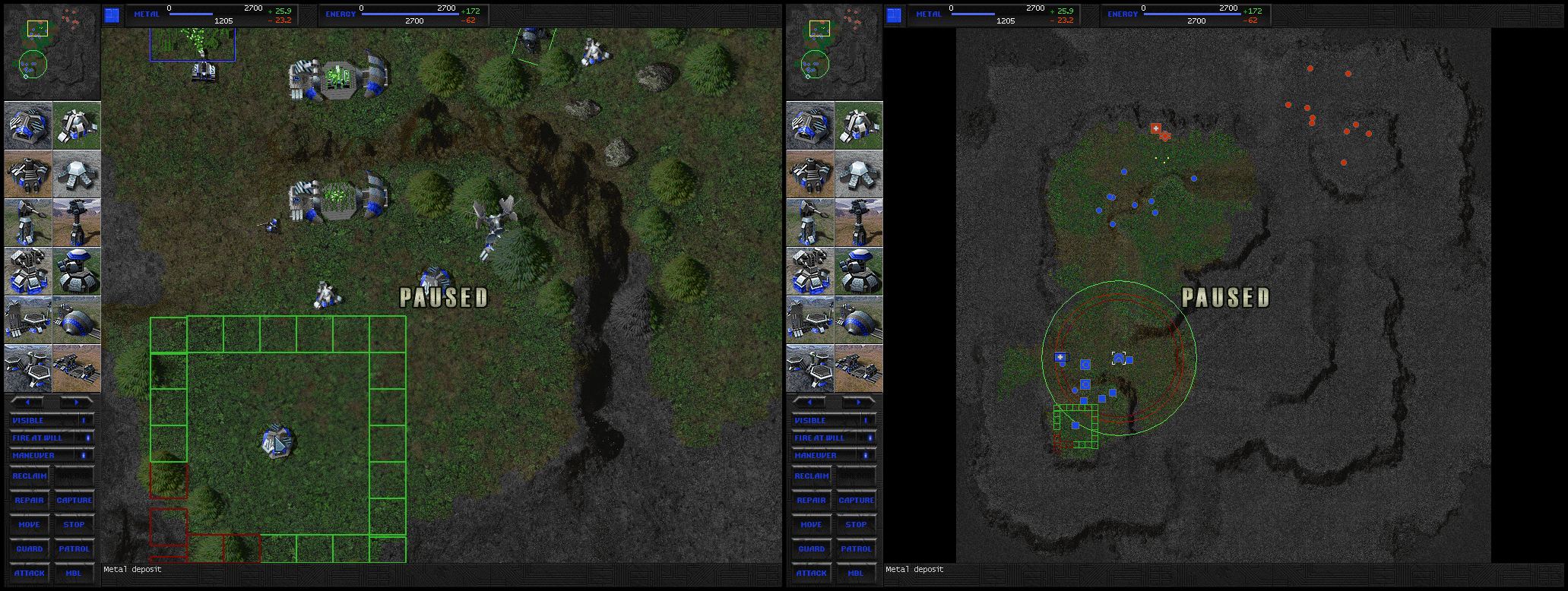 TA Zero Alpha 4 « TA Zero20 janeiro 2025
TA Zero Alpha 4 « TA Zero20 janeiro 2025 -
 Street Fighter Zero 2 Alpha (Asia 960826) ROM Download - Free CPS 2 Games - Retrostic20 janeiro 2025
Street Fighter Zero 2 Alpha (Asia 960826) ROM Download - Free CPS 2 Games - Retrostic20 janeiro 2025 -
 Zero Alpha – IT is worry-free for your business20 janeiro 2025
Zero Alpha – IT is worry-free for your business20 janeiro 2025 -
 Will AlphaZero become available to the public? : r/chess20 janeiro 2025
Will AlphaZero become available to the public? : r/chess20 janeiro 2025 -
 Cartoon Street png download - 1062*753 - Free Transparent Street Fighter Alpha png Download. - CleanPNG / KissPNG20 janeiro 2025
Cartoon Street png download - 1062*753 - Free Transparent Street Fighter Alpha png Download. - CleanPNG / KissPNG20 janeiro 2025

você pode gostar
-
 Checkmate Powerboat Boat Decals - 2 Color! - Style 220 janeiro 2025
Checkmate Powerboat Boat Decals - 2 Color! - Style 220 janeiro 2025 -
Spirit Blossom Yone20 janeiro 2025
-
 King Of The Hill - intro King of the hill, Quad city djs20 janeiro 2025
King Of The Hill - intro King of the hill, Quad city djs20 janeiro 2025 -
 Bug Reporter in Code Plugins - UE Marketplace20 janeiro 2025
Bug Reporter in Code Plugins - UE Marketplace20 janeiro 2025 -
 🔴 Black Friday AO VIVO com sorteio de PS5! Buscando ofertas de20 janeiro 2025
🔴 Black Friday AO VIVO com sorteio de PS5! Buscando ofertas de20 janeiro 2025 -
 Boxy-Boo Plush Toy Horror Monster Stuffed Animal Plushie Doll Toys for Boys Girls Birthday Easter Gifts20 janeiro 2025
Boxy-Boo Plush Toy Horror Monster Stuffed Animal Plushie Doll Toys for Boys Girls Birthday Easter Gifts20 janeiro 2025 -
 Padrão Xadrez Colorido, Quadriculado Royalty Free SVG, Cliparts, Vetores, e Ilustrações Stock. Image 14961807020 janeiro 2025
Padrão Xadrez Colorido, Quadriculado Royalty Free SVG, Cliparts, Vetores, e Ilustrações Stock. Image 14961807020 janeiro 2025 -
 House Of The Dragon': HBO Reveals 'Game Of Thrones' Prequel In Production – Deadline20 janeiro 2025
House Of The Dragon': HBO Reveals 'Game Of Thrones' Prequel In Production – Deadline20 janeiro 2025 -
 a eddsworld screenshot edit with the old 2004 designs : r/Eddsworld20 janeiro 2025
a eddsworld screenshot edit with the old 2004 designs : r/Eddsworld20 janeiro 2025 -
 Steep stairs on a mountain side on the Inca trail at Machu Picchu Wall Art, Canvas Prints, Framed Prints, Wall Peels20 janeiro 2025
Steep stairs on a mountain side on the Inca trail at Machu Picchu Wall Art, Canvas Prints, Framed Prints, Wall Peels20 janeiro 2025