Policy or Value ? Loss Function and Playing Strength in AlphaZero
Por um escritor misterioso
Last updated 18 dezembro 2024

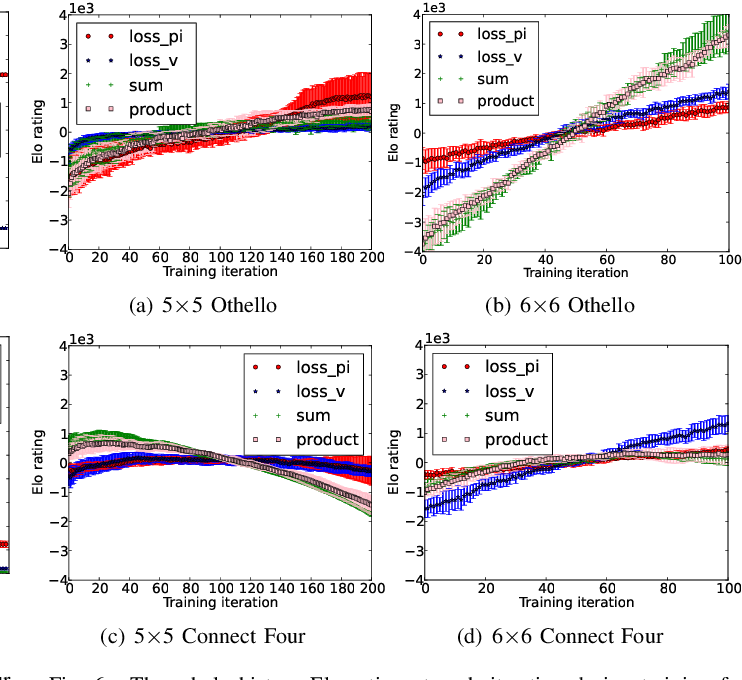
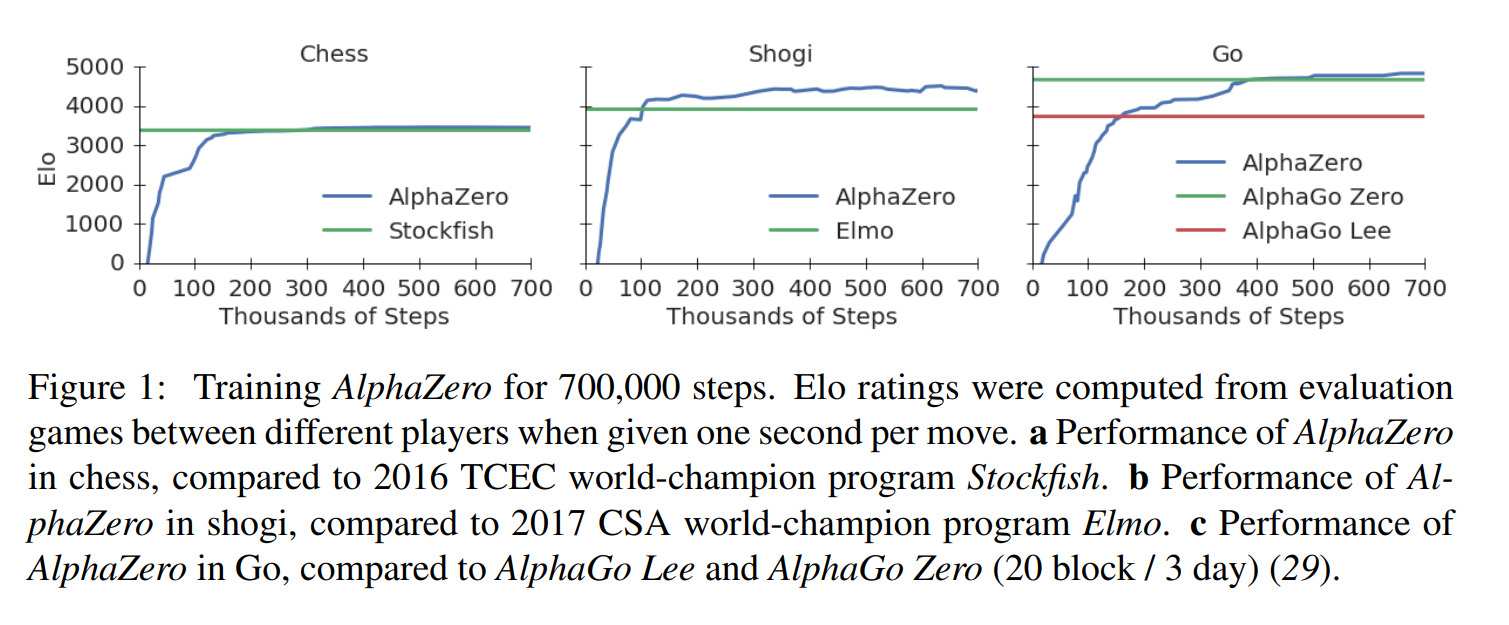
Results indicate that, at least for relatively simple games such as 6x6 Othello and Connect Four, optimizing the sum, as AlphaZero does, performs consistently worse than other objectives, in particular by optimizing only the value loss. Recently, AlphaZero has achieved outstanding performance in playing Go, Chess, and Shogi. Players in AlphaZero consist of a combination of Monte Carlo Tree Search and a Deep Q-network, that is trained using self-play. The unified Deep Q-network has a policy-head and a value-head. In AlphaZero, during training, the optimization minimizes the sum of the policy loss and the value loss. However, it is not clear if and under which circumstances other formulations of the objective function are better. Therefore, in this paper, we perform experiments with combinations of these two optimization targets. Self-play is a computationally intensive method. By using small games, we are able to perform multiple test cases. We use a light-weight open source reimplementation of AlphaZero on two different games. We investigate optimizing the two targets independently, and also try different combinations (sum and product). Our results indicate that, at least for relatively simple games such as 6x6 Othello and Connect Four, optimizing the sum, as AlphaZero does, performs consistently worse than other objectives, in particular by optimizing only the value loss. Moreover, we find that care must be taken in computing the playing strength. Tournament Elo ratings differ from training Elo ratings—training Elo ratings, though cheap to compute and frequently reported, can be misleading and may lead to bias. It is currently not clear how these results transfer to more complex games and if there is a phase transition between our setting and the AlphaZero application to Go where the sum is seemingly the better choice.
Mastering Atari, Go, chess and shogi by planning with a learned model

AlphaGo Zero – How and Why it Works – Tim Wheeler
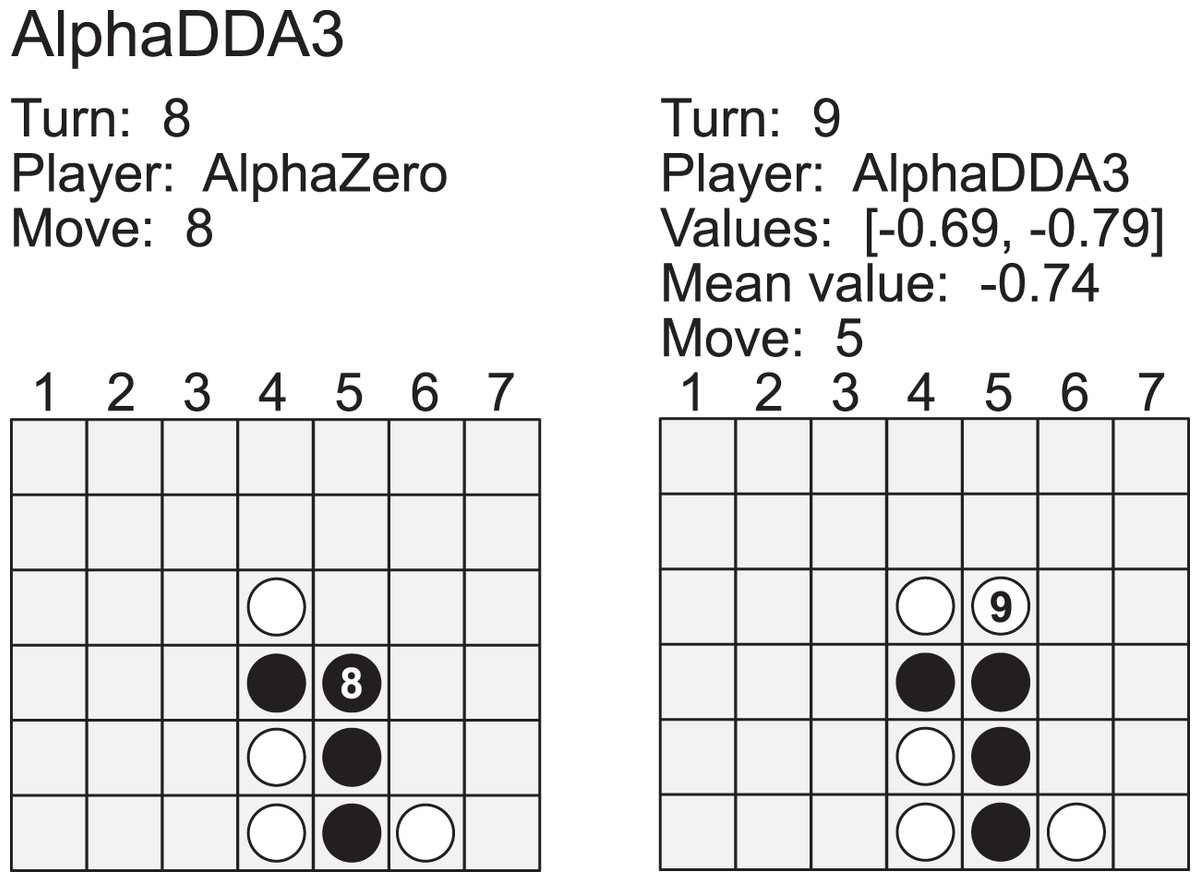
AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]
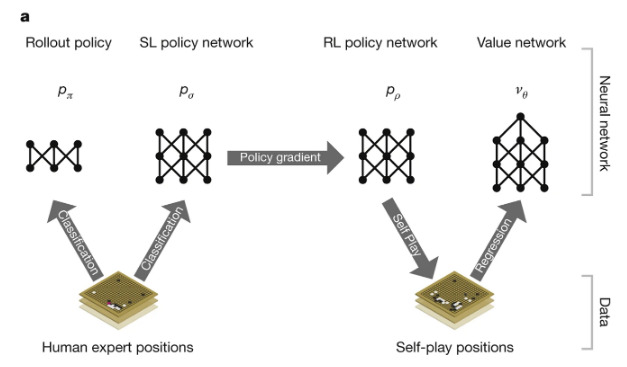
RankNet for evaluation functions of the game of Go - IOS Press
Policy or Value ? Loss Function and Playing Strength in AlphaZero-like Self- play
AlphaZero Explained · On AI
Policy or Value ? Loss Function and Playing Strength in AlphaZero-like Self- play
AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]
AlphaGo/AlphaGoZero/AlphaZero/MuZero: Mastering games using progressively fewer priors
AlphaGo/AlphaGoZero/AlphaZero/MuZero: Mastering games using progressively fewer priors
Recomendado para você
-
 Multiplayer AlphaZero18 dezembro 2024
Multiplayer AlphaZero18 dezembro 2024 -
 Simple Alpha Zero18 dezembro 2024
Simple Alpha Zero18 dezembro 2024 -
![AlphaGo Zero] Mastering the game of Go without human knowledge](https://i.ytimg.com/vi/_x9bXso3wo4/sddefault.jpg) AlphaGo Zero] Mastering the game of Go without human knowledge18 dezembro 2024
AlphaGo Zero] Mastering the game of Go without human knowledge18 dezembro 2024 -
 Efficient Learning for AlphaZero via Path Consistency Poster18 dezembro 2024
Efficient Learning for AlphaZero via Path Consistency Poster18 dezembro 2024 -
 Alpha S 2 Pickleball Paddle Bundle - Pickleball Paddle Shop18 dezembro 2024
Alpha S 2 Pickleball Paddle Bundle - Pickleball Paddle Shop18 dezembro 2024 -
 Contributing to Leela Chess Zero. Creating the Caissa of Chess engines. - Leela Chess Zero18 dezembro 2024
Contributing to Leela Chess Zero. Creating the Caissa of Chess engines. - Leela Chess Zero18 dezembro 2024 -
![MCQ] If α and β are the zeros of a polynomial f(x) = px2 – 2x + 3p](https://d1avenlh0i1xmr.cloudfront.net/5c6616c9-a254-4cb6-b0aa-2b54f21e9cb3/slide6.jpg) MCQ] If α and β are the zeros of a polynomial f(x) = px2 – 2x + 3p18 dezembro 2024
MCQ] If α and β are the zeros of a polynomial f(x) = px2 – 2x + 3p18 dezembro 2024 -
Alpha Kappa Alpha Sorority, Incorporated - Rho Xi Omega Chapter18 dezembro 2024
-
How AlphaZero Learns Chess?. DeepMind and Google Brain researchers18 dezembro 2024
-
 What is Q*? And when we will hear more? - Community - OpenAI Developer Forum18 dezembro 2024
What is Q*? And when we will hear more? - Community - OpenAI Developer Forum18 dezembro 2024

você pode gostar
-
 Crunchyroll Expo 2022 061, Michael Ocampo18 dezembro 2024
Crunchyroll Expo 2022 061, Michael Ocampo18 dezembro 2024 -
 1125x2436 Batman Walking 4k Iphone XS,Iphone 10,Iphone X HD 4k Wallpapers, Images, Backgrounds, Photos and Pictures18 dezembro 2024
1125x2436 Batman Walking 4k Iphone XS,Iphone 10,Iphone X HD 4k Wallpapers, Images, Backgrounds, Photos and Pictures18 dezembro 2024 -
 Mahjong Soul x Code Geass: Lelouch of the Rebellion Collab Runs18 dezembro 2024
Mahjong Soul x Code Geass: Lelouch of the Rebellion Collab Runs18 dezembro 2024 -
 Feature Spotlight - Three Races , Three Gameplays - Fractured - The Dynamic MMO18 dezembro 2024
Feature Spotlight - Three Races , Three Gameplays - Fractured - The Dynamic MMO18 dezembro 2024 -
 How to play Phantom Forces with a PS4/PS5 Controller in 202218 dezembro 2024
How to play Phantom Forces with a PS4/PS5 Controller in 202218 dezembro 2024 -
W or L ? #kinglegacy #bloxfruits #string #edit #gameedit #fy #fyp #fyp18 dezembro 2024
-
 Astro Boy Character Cartoon, Personagens Robotboy, desenhos animados, flor, cauda png18 dezembro 2024
Astro Boy Character Cartoon, Personagens Robotboy, desenhos animados, flor, cauda png18 dezembro 2024 -
 Poppy Debuts New Song Eat at Grammys 2021 Premiere Ceremony18 dezembro 2024
Poppy Debuts New Song Eat at Grammys 2021 Premiere Ceremony18 dezembro 2024 -
 I played Noob archer, Poki games18 dezembro 2024
I played Noob archer, Poki games18 dezembro 2024 -
 Retiro Official English Website for the City of Buenos Aires18 dezembro 2024
Retiro Official English Website for the City of Buenos Aires18 dezembro 2024
