XQuAD Dataset Papers With Code
Por um escritor misterioso
Last updated 18 dezembro 2024

XQuAD (Cross-lingual Question Answering Dataset) is a benchmark dataset for evaluating cross-lingual question answering performance. The dataset consists of a subset of 240 paragraphs and 1190 question-answer pairs from the development set of SQuAD v1.1 (Rajpurkar et al., 2016) together with their professional translations into ten languages: Spanish, German, Greek, Russian, Turkish, Arabic, Vietnamese, Thai, Chinese, and Hindi. Consequently, the dataset is entirely parallel across 11 languages.

PDF] VulBERTa: Simplified Source Code Pre-Training for
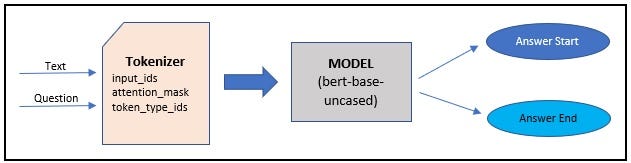
Fine tuning a Question Answering model using SQuAD and BERT

An example from the SQuAD dataset. Evidences needed for the answer

PGPS9K Dataset Papers With Code

PDF] i-Code: An Integrative and Composable Multimodal Learning
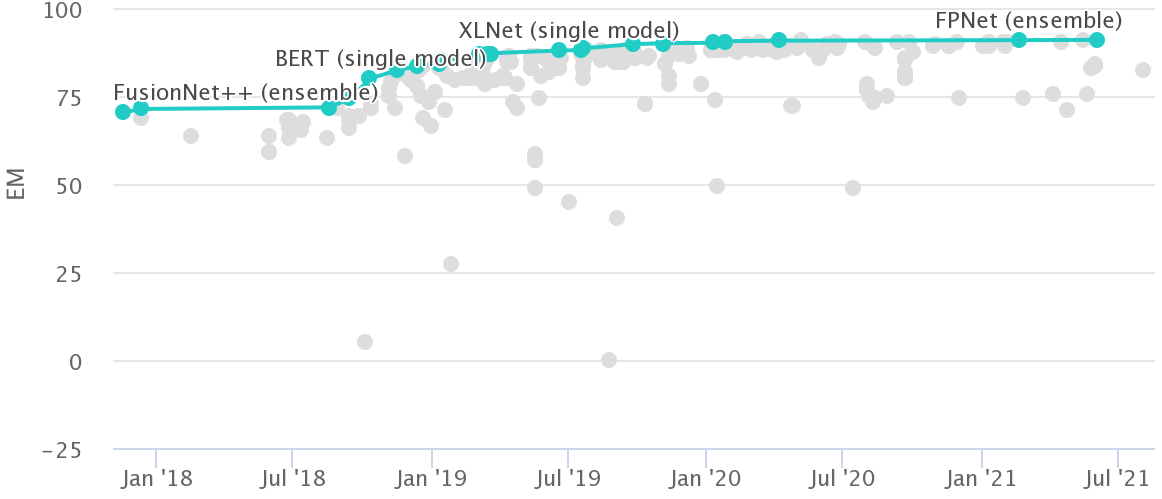
Challenges and Opportunities in NLP Benchmarking

An Overview of Image Data Augmentation
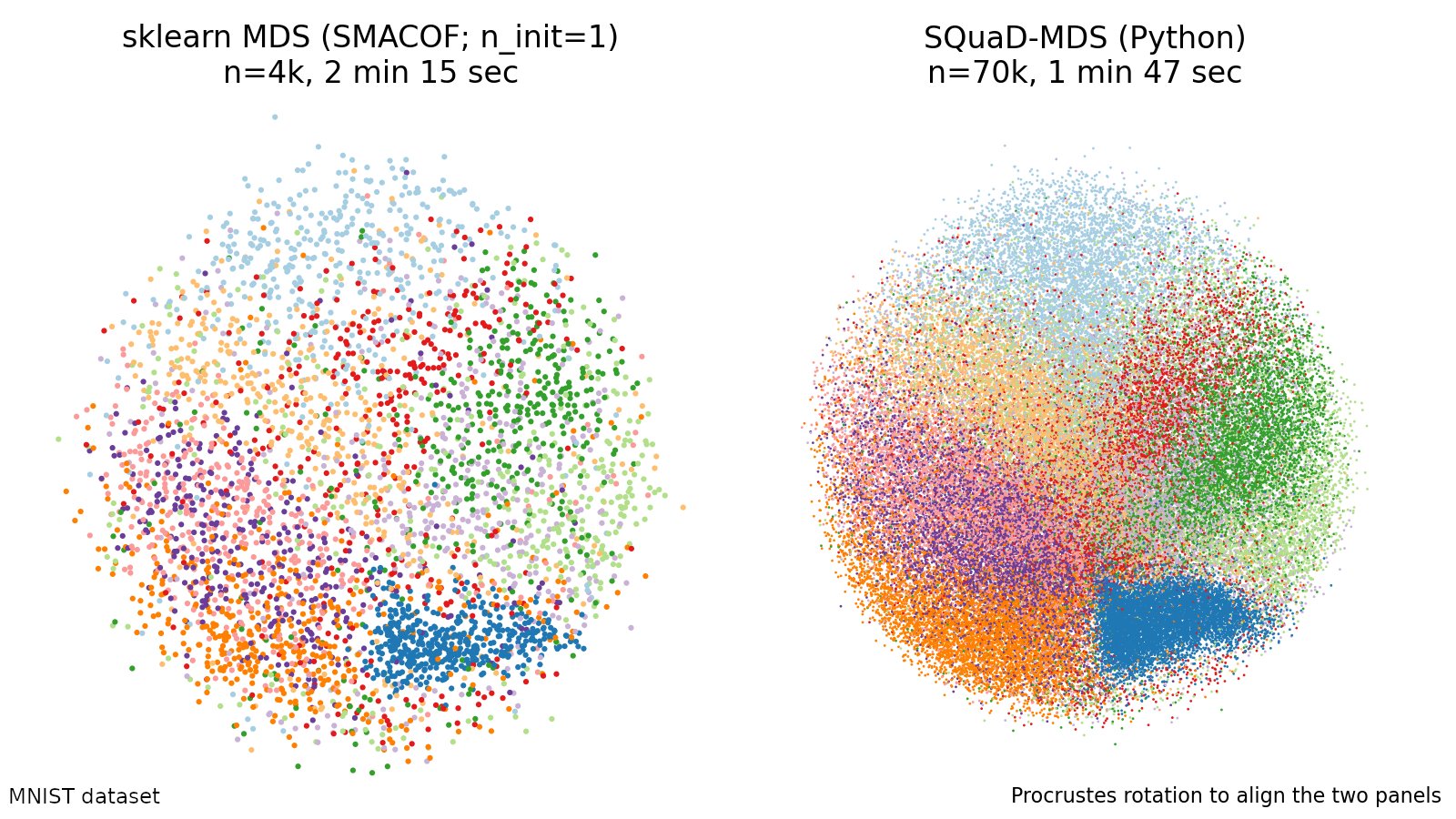
Dmitry Kobak on X: Really cool work by Pierre Lambert et al

How to Answer Questions with Machine Learning

Datasets em português - NLP com o Deep Learning - AI Lab Deep
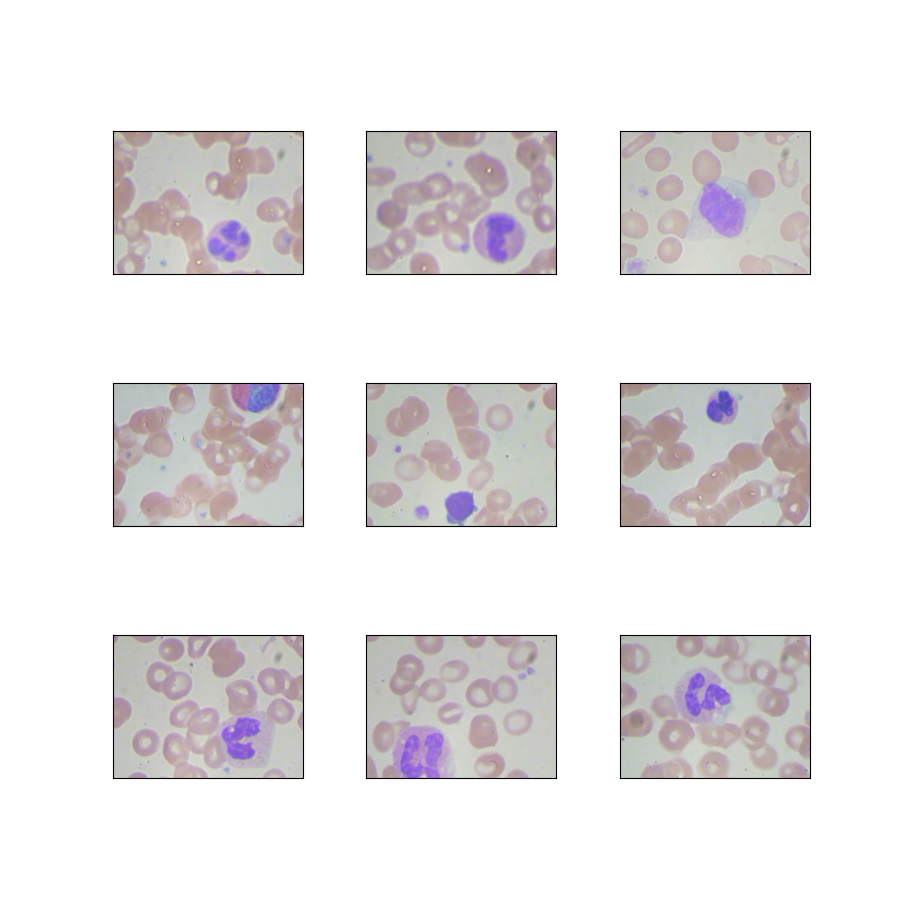
bccd TensorFlow Datasets

XQA Dataset Papers With Code

Papers With Code Machine Learning Papers and Code Free Resource
Recomendado para você
-
Internal Combustion Engine Question and Answer, PDF, Internal Combustion Engine18 dezembro 2024
-
 Books :: Marine & Nautical :: Marine Engineering :: Lamb's Questions & Answers on the Marine Diesel Engine, 8th Edition18 dezembro 2024
Books :: Marine & Nautical :: Marine Engineering :: Lamb's Questions & Answers on the Marine Diesel Engine, 8th Edition18 dezembro 2024 -
This Set of Ic Engines Multiple Choice Questions & Answers (MCQS) Focuses On Battery Ignition System, PDF, Ignition System18 dezembro 2024
-
 CDL Test Flashcards Questions and Answers Already Passed18 dezembro 2024
CDL Test Flashcards Questions and Answers Already Passed18 dezembro 2024 -
 PDF) THERMAL ENGINEERING -I UNIT -III SHORT QUESTIONS AND ANSWERS INTERNAL COMBUSTION ENGINES18 dezembro 2024
PDF) THERMAL ENGINEERING -I UNIT -III SHORT QUESTIONS AND ANSWERS INTERNAL COMBUSTION ENGINES18 dezembro 2024 -
 Dk & Eng - Engine - Page 1 - Witherbys18 dezembro 2024
Dk & Eng - Engine - Page 1 - Witherbys18 dezembro 2024 -
 Top 122 SEO Interview Questions and Answers - Shiksha Online18 dezembro 2024
Top 122 SEO Interview Questions and Answers - Shiksha Online18 dezembro 2024 -
 ART101 - Courtney Rowles - Chapter 1 Worksheet.pdf - 1 Chapter pter The Automobile Courtney Rowles Name March 10 Date Mr. Lindsay Instructor Score18 dezembro 2024
ART101 - Courtney Rowles - Chapter 1 Worksheet.pdf - 1 Chapter pter The Automobile Courtney Rowles Name March 10 Date Mr. Lindsay Instructor Score18 dezembro 2024 -
![Aug 11, 2023] C_MDG_1909 Dumps PDF and Test Engine Exam Questions - Actual4test [Q47-Q64]](https://www.actual4test.com/uploads/imgs/C_MDG_1909-banner_a244691_c84e8557f5e72d4181ff046a93acfbf2.jpg) Aug 11, 2023] C_MDG_1909 Dumps PDF and Test Engine Exam Questions - Actual4test [Q47-Q64]18 dezembro 2024
Aug 11, 2023] C_MDG_1909 Dumps PDF and Test Engine Exam Questions - Actual4test [Q47-Q64]18 dezembro 2024 -
 Top 30 Mobile Testing Interview Questions & Answers for 202318 dezembro 2024
Top 30 Mobile Testing Interview Questions & Answers for 202318 dezembro 2024


você pode gostar
-
 o que significa cálice de deus no blox fruits18 dezembro 2024
o que significa cálice de deus no blox fruits18 dezembro 2024 -
 Saúdepets - Planos de Saúde Pet - Consultoria on X: Sou muito fofo! I'm Very fluffy! #cao #cachorro #canino #dog #pet #animal #puppy / X18 dezembro 2024
Saúdepets - Planos de Saúde Pet - Consultoria on X: Sou muito fofo! I'm Very fluffy! #cao #cachorro #canino #dog #pet #animal #puppy / X18 dezembro 2024 -
Criança em quarentena brinca sim18 dezembro 2024
-
 Anime Rokudenashi Majutsu Koushi to Akashic Records HD Wallpaper18 dezembro 2024
Anime Rokudenashi Majutsu Koushi to Akashic Records HD Wallpaper18 dezembro 2024 -
 contando o jogo infantil de comida de inverno dos desenhos18 dezembro 2024
contando o jogo infantil de comida de inverno dos desenhos18 dezembro 2024 -
 Kakashi Hatake by AlucardNoLife Kakashi, Coloriage naruto, Manga18 dezembro 2024
Kakashi Hatake by AlucardNoLife Kakashi, Coloriage naruto, Manga18 dezembro 2024 -
 Cities: Skylines 2 offers much deeper control over its economy and production over original - Neowin18 dezembro 2024
Cities: Skylines 2 offers much deeper control over its economy and production over original - Neowin18 dezembro 2024 -
 Jogos de futebol hoje (03/11/23) ao vivo: horário e onde assistir18 dezembro 2024
Jogos de futebol hoje (03/11/23) ao vivo: horário e onde assistir18 dezembro 2024 -
Crackers Wither Storm Mod MCPE – Apps no Google Play18 dezembro 2024
-
Gabe vendo Jujutsu Kaisen, Twitch - @gabepeixe #jujutsukaisen #jujuts18 dezembro 2024


