PDF] Page frame detection for double page document images
Por um escritor misterioso
Last updated 18 dezembro 2024
![PDF] Page frame detection for double page document images](https://d3i71xaburhd42.cloudfront.net/b6f355361ab48262d656a65fc6095f4ab8301ed8/8-Figure12-1.png)
A novel algorithm for detecting the page frames on double page document images by applying a pre-processing which includes binarization, noise removal and image smoothing is proposed. Scanning two book pages at the same time helps to accelerate the scanning process but on the other hand introduces several difficulties if the user needs to have one page per image. A major difficulty is the appearance of noisy black borders around text areas as well as of noisy black stripes between the two pages. In this paper, we propose a novel algorithm for detecting the page frames on double page document images. Our aim is to split the image into the two pages as well as to remove noisy borders. First we apply a pre-processing which includes binarization, noise removal and image smoothing. Then, we detect the vertical zones of the two pages. In this stage, we introduce the vertical white run projections which have been proved efficient for detecting vertical zones of text areas. Finally, the horizontal zones of the two pages are detected based on horizontal white run projections. The experimental results on several double page document images from fifteen different books demonstrate the effectiveness of the proposed technique.
![PDF] Page frame detection for double page document images](https://upload.wikimedia.org/wikipedia/commons/thumb/1/17/Prinicipia-title.png/640px-Prinicipia-title.png)
Philosophiæ Naturalis Principia Mathematica - Wikipedia
![PDF] Page frame detection for double page document images](https://d3i71xaburhd42.cloudfront.net/b6f355361ab48262d656a65fc6095f4ab8301ed8/2-Figure2-1.png)
PDF] Page frame detection for double page document images
![PDF] Page frame detection for double page document images](https://www.cdc.gov/mmwr/volumes/70/wr/social-media/mm7003e2_SARSCoV2Variant_IMAGE_15Jan21_1200x675-medium.jpg?_=18898)
Emergence of SARS-CoV-2 B.1.1.7 Lineage — United States, December 29, 2020–January 12, 2021
![PDF] Page frame detection for double page document images](https://pspdfkit.com/assets/images/blog/2021/how-to-embed-a-pdf-viewer-in-your-website/article-header-6e02070a.png)
How to Embed a PDF Viewer in Your Website
![PDF] Page frame detection for double page document images](https://www.researchgate.net/profile/Nikolaos-Stamatopoulos-2/publication/220933023/figure/fig1/AS:305659548585984@1449886323026/An-example-of-a-double-page-document-image_Q320.jpg)
PDF) Page frame detection for double page document images
![PDF] Page frame detection for double page document images](https://storage.googleapis.com/website-production/uploads/2023/04/110-landing-page-examples.webp)
110 Landing Page Examples That You Can't Afford to Miss (2023)
![PDF] Page frame detection for double page document images](https://www.drscripto.com/wp-content/uploads/2017/03/Indesign-Place-PDF_Dialog_610x343px.jpg)
Place multiple paged PDF into existing image frames – Dr Scripto
![PDF] Page frame detection for double page document images](https://webstore.ansi.org/cover-pages/small/ASTM/F2208-08R19.jpg)
ASTM F2208-08(2019) - Standard Safety Specification for Residential Pool Alarms
![PDF] Page frame detection for double page document images](https://isobellynx.com/wp-content/uploads/2018/07/acrobat-trick-1-768x216.png)
How to remove Headers and Footers from a PDF even if Acrobat doesn't detect them
Document Detection in Python. Building a simple document detector…, by Shakleen Ishfar, intelligentmachines
![PDF] Page frame detection for double page document images](https://miro.medium.com/v2/resize:fit:1400/1*8bOHwjKOGyF6SAPB240qYQ.png)
How to Create a PDF Report for Your Data Analysis in Python, by Leonie Monigatti
![PDF] Page frame detection for double page document images](https://help.apple.com/assets/6525D4ADDA94B955F800FD2A/6525D4B0E1BC06297403C97C/en_US/3bfdf6299b4eda1f760128e80aa81717.png)
Scan text and documents in Notes using the iPad camera - Apple Support
![PDF] Page frame detection for double page document images](https://miro.medium.com/v2/resize:fit:1358/1*SLwrjTpeOD4MpwrYqJUBmg.png)
How to Scrape and Extract Data from PDFs Using Python and tabula-py, by Aaron Zhu
Recomendado para você
-
 From Zero to Hero Send AWS SES Emails Like a Pro! - DEV Community18 dezembro 2024
From Zero to Hero Send AWS SES Emails Like a Pro! - DEV Community18 dezembro 2024 -
 The #BodegaStrike is giving New Yorkers all the feels18 dezembro 2024
The #BodegaStrike is giving New Yorkers all the feels18 dezembro 2024 -
 Automated Planning Tool makes work order allocation more efficient18 dezembro 2024
Automated Planning Tool makes work order allocation more efficient18 dezembro 2024 -
 Re)Drawing Histories18 dezembro 2024
Re)Drawing Histories18 dezembro 2024 -
 Oliver Twist and Great Expectations by Charles Dickens / 1930s Illustrated Edition / Red Faux Leather, Gilt Decoration/ In Good Condition18 dezembro 2024
Oliver Twist and Great Expectations by Charles Dickens / 1930s Illustrated Edition / Red Faux Leather, Gilt Decoration/ In Good Condition18 dezembro 2024 -
 Version 2.3.2, Mails are not sent SSL is not renewed - General18 dezembro 2024
Version 2.3.2, Mails are not sent SSL is not renewed - General18 dezembro 2024 -
 Vintage Sears Coldspot Freezer Owner's Manual Care Operation18 dezembro 2024
Vintage Sears Coldspot Freezer Owner's Manual Care Operation18 dezembro 2024 -
 SES Emails Going to Spam and What To Do About It18 dezembro 2024
SES Emails Going to Spam and What To Do About It18 dezembro 2024 -
 An error occurred while trying to load this page. - Flarum Community18 dezembro 2024
An error occurred while trying to load this page. - Flarum Community18 dezembro 2024 -
 k=gmail.main.en18 dezembro 2024
k=gmail.main.en18 dezembro 2024
você pode gostar
-
 Demon Slayer: Swordsmith Village (Season 3) Episode 8 Preview Revealed - Anime Corner18 dezembro 2024
Demon Slayer: Swordsmith Village (Season 3) Episode 8 Preview Revealed - Anime Corner18 dezembro 2024 -
 Summertime Saga 0.20 - Download for PC Free18 dezembro 2024
Summertime Saga 0.20 - Download for PC Free18 dezembro 2024 -
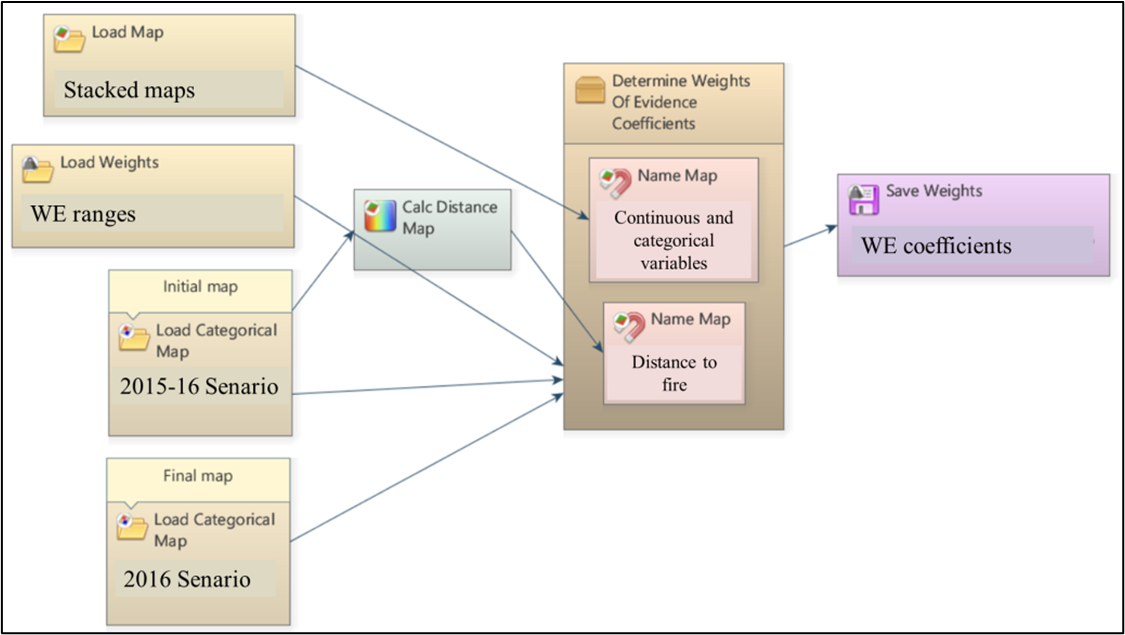 Exploração madeireira e incêndios florestais: 8 – Métodos para avaliar a vulnerabilidade a incêndio - Amazônia Real18 dezembro 2024
Exploração madeireira e incêndios florestais: 8 – Métodos para avaliar a vulnerabilidade a incêndio - Amazônia Real18 dezembro 2024 -
hghghghgh Nova Skin18 dezembro 2024
-
Como desenhar o TTACHI UCHIHA (Naruto] pásso a passo, fácil e18 dezembro 2024
-
 Discuss Everything About Animator vs. Animation Wiki18 dezembro 2024
Discuss Everything About Animator vs. Animation Wiki18 dezembro 2024 -
Leve Um Kit C/ 2 Super Jogos 1 UNO + 1 Jogo Completo Tabuleiro de Xadrez Para Jogar Toda Família18 dezembro 2024
-
 Nextbots In Backrooms: Obunga APK + Mod 1.1.5a - Download Free for Android18 dezembro 2024
Nextbots In Backrooms: Obunga APK + Mod 1.1.5a - Download Free for Android18 dezembro 2024 -
 Typebot: Free Open Source Chatbot Builder18 dezembro 2024
Typebot: Free Open Source Chatbot Builder18 dezembro 2024 -
 Os 10 Melhores Filmes de Terror de 2022 - CinePOP18 dezembro 2024
Os 10 Melhores Filmes de Terror de 2022 - CinePOP18 dezembro 2024
![Como desenhar o TTACHI UCHIHA (Naruto] pásso a passo, fácil e](https://www.tiktok.com/api/img/?itemId=7247132269272468741&location=0&aid=1988)
