AlphaDDA: strategies for adjusting the playing strength of a fully
Por um escritor misterioso
Last updated 09 janeiro 2025
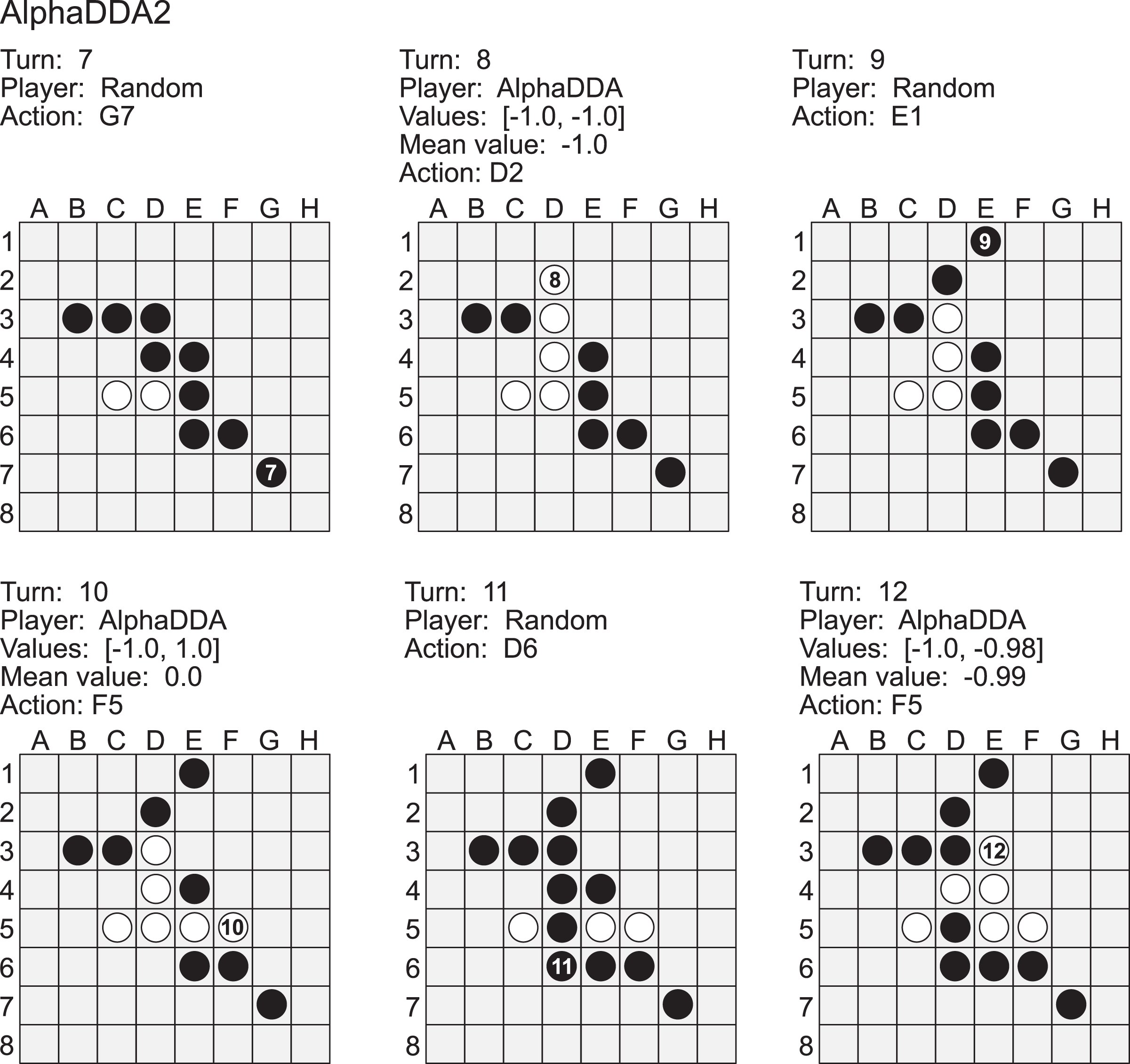
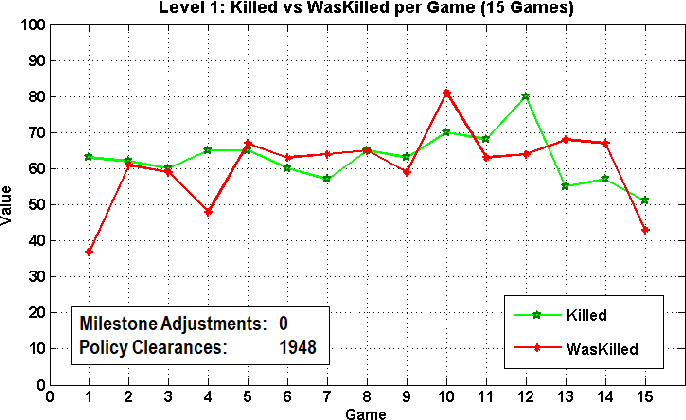
Artificial intelligence (AI) has achieved superhuman performance in board games such as Go, chess, and Othello (Reversi). In other words, the AI system surpasses the level of a strong human expert player in such games. In this context, it is difficult for a human player to enjoy playing the games with the AI. To keep human players entertained and immersed in a game, the AI is required to dynamically balance its skill with that of the human player. To address this issue, we propose AlphaDDA, an AlphaZero-based AI with dynamic difficulty adjustment (DDA). AlphaDDA consists of a deep neural network (DNN) and a Monte Carlo tree search, as in AlphaZero. AlphaDDA learns and plays a game the same way as AlphaZero, but can change its skills. AlphaDDA estimates the value of the game state from only the board state using the DNN. AlphaDDA changes a parameter dominantly controlling its skills according to the estimated value. Consequently, AlphaDDA adjusts its skills according to a game state. AlphaDDA can adjust its skill using only the state of a game without any prior knowledge regarding an opponent. In this study, AlphaDDA plays Connect4, Othello, and 6x6 Othello with other AI agents. Other AI agents are AlphaZero, Monte Carlo tree search, the minimax algorithm, and a random player. This study shows that AlphaDDA can balance its skill with that of the other AI agents, except for a random player. AlphaDDA can weaken itself according to the estimated value. However, AlphaDDA beats the random player because AlphaDDA is stronger than a random player even if AlphaDDA weakens itself to the limit. The DDA ability of AlphaDDA is based on an accurate estimation of the value from the state of a game. We believe that the AlphaDDA approach for DDA can be used for any game AI system if the DNN can accurately estimate the value of the game state and we know a parameter controlling the skills of the AI system.

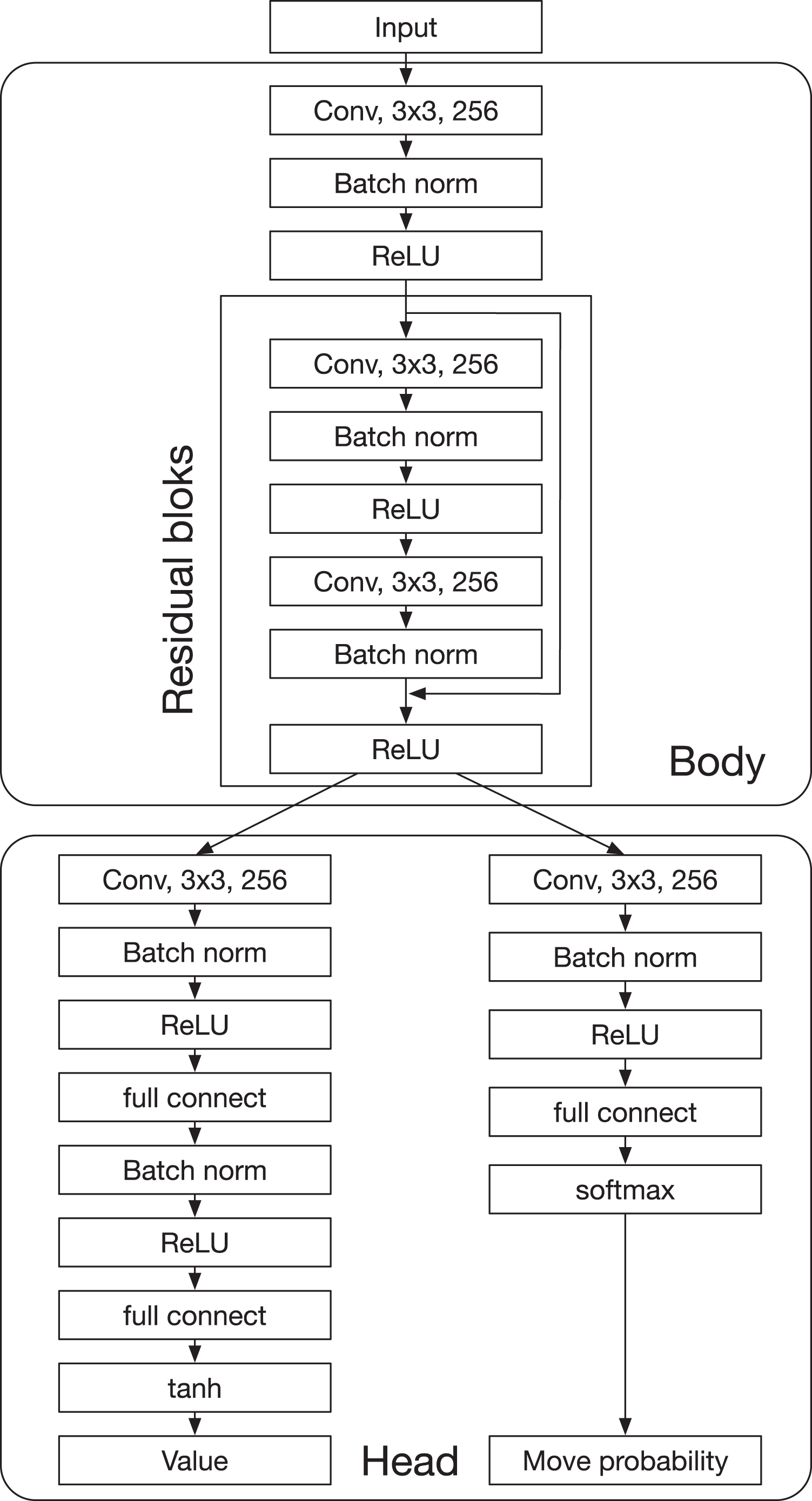
Figure A1 Deep neural network of AlphaDDA. Full-size DOI

Difficult flow of the player, adapted from Hunicke and Chapman [7]

Understanding Employees' Strengths Helps Aligning Them with Tasks
An overview of Skilled Experience Catalogue.

Classification outcome in terms of error rate for given 3-mode tensor
AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]
New Seated Adaptive Strength Training Program with Logan Aldridge & New Collection in Collaboration with the Christopher & Dana Reeve Foundation - Peloton Buddy

PDF] Skilled Experience Catalogue: A Skill-Balancing Mechanism for Non- Player Characters using Reinforcement Learning
Mastering the Card Game of Jaipur Through Zero-Knowledge Self-Play Reinforcement Learning and Action Masks

Build Alpha Reviews, Trading Reviews and Vendors

Mastering the Card Game of Jaipur Through Zero-Knowledge Self-Play Reinforcement Learning and Action Masks

AlphaZero for a Non-Deterministic Game
PDF] Skilled Experience Catalogue: A Skill-Balancing Mechanism for Non- Player Characters using Reinforcement Learning
Recomendado para você
-
 Acquisition of chess knowledge in AlphaZero09 janeiro 2025
Acquisition of chess knowledge in AlphaZero09 janeiro 2025 -
 Google AI Achieves Alien Superhuman Mastery of Chess and Go in Mere Hours - The New Stack09 janeiro 2025
Google AI Achieves Alien Superhuman Mastery of Chess and Go in Mere Hours - The New Stack09 janeiro 2025 -
 AlphaZero from Scratch – Machine Learning Tutorial09 janeiro 2025
AlphaZero from Scratch – Machine Learning Tutorial09 janeiro 2025 -
Is there an Open Source version of AlphaZero? (specifically, the generic game-learning tool, distinct from AlphaGo) - Quora09 janeiro 2025
-
 GitHub - junxiaosong/AlphaZero_Gomoku: An implementation of the09 janeiro 2025
GitHub - junxiaosong/AlphaZero_Gomoku: An implementation of the09 janeiro 2025 -
 GitHub - CogitoNTNU/AlphaZero: An implementation of AlphaZero09 janeiro 2025
GitHub - CogitoNTNU/AlphaZero: An implementation of AlphaZero09 janeiro 2025 -
 动手实现并行版AlphaZero · hijkzzz/alpha-zero-gomoku Wiki · GitHub09 janeiro 2025
动手实现并行版AlphaZero · hijkzzz/alpha-zero-gomoku Wiki · GitHub09 janeiro 2025 -
alpha-zero · GitHub Topics · GitHub09 janeiro 2025
-
 AlphaZero implementation and tutorial, by Darin Straus09 janeiro 2025
AlphaZero implementation and tutorial, by Darin Straus09 janeiro 2025 -
 AlphaZero - Chessprogramming wiki09 janeiro 2025
AlphaZero - Chessprogramming wiki09 janeiro 2025
você pode gostar
-
 STL file Call Of Duty Modern Warfare Ghost Jawbone Operator Mask09 janeiro 2025
STL file Call Of Duty Modern Warfare Ghost Jawbone Operator Mask09 janeiro 2025 -
 Sudoku Para Imprimir 3809 janeiro 2025
Sudoku Para Imprimir 3809 janeiro 2025 -
 Gaming Website Template - Free PSD - Freebie Supply09 janeiro 2025
Gaming Website Template - Free PSD - Freebie Supply09 janeiro 2025 -
 Almost all my desktop game icons have switched to this ugly white paper icon. How do I fix? : r/Windows1109 janeiro 2025
Almost all my desktop game icons have switched to this ugly white paper icon. How do I fix? : r/Windows1109 janeiro 2025 -
 xadrez Verifica patten dentro azul, Preto .desatado tecido textura para imprimir. 20271409 Vetor no Vecteezy09 janeiro 2025
xadrez Verifica patten dentro azul, Preto .desatado tecido textura para imprimir. 20271409 Vetor no Vecteezy09 janeiro 2025 -
 The Human Bullet (1968)09 janeiro 2025
The Human Bullet (1968)09 janeiro 2025 -
Xbox PC game pass saying I need to subscribe even tho I am? - Microsoft Community09 janeiro 2025
-
 Soul Eater
Soul Eater
Graphic Novels09 janeiro 2025 -
SCP-1471 MalO by SiaM_FoXX, SCP-147109 janeiro 2025
-
 STL file Squirtle muscle・3D printing design to download・Cults09 janeiro 2025
STL file Squirtle muscle・3D printing design to download・Cults09 janeiro 2025

