DeepMind's MuZero teaches itself how to win at Atari, chess, shogi, and Go
Por um escritor misterioso
Last updated 17 novembro 2024

In a preprint paper, researchers at Alphabet's DeepMind detail MuZero, an algorithm that effectively teaches itself how to play Atari and board games.

Listen to DeepMind: The Podcast podcast

Inside AI Companies: Top 10 Innovations by Google DeepMind So Far

Mastering Atari, Go, chess and shogi by planning with a learned model

DeepMind Comes Out With “Player Of Games”: Masters Both Perfect And Imperfect Information Games
How does the computer program AlphaZero determine which move to make in chess? Is there any insight that can be gained from looking at its strategy? - Quora

DeepMind's New AI Masters Games Without Even Being Taught the Rules - IEEE Spectrum

A historical tale of DeepMind's games

AlphaGo - Google DeepMind

DeepMind Introduces MuZero That Achieves Superhuman Performance In Tasks Without Learning Their Underlying Dynamics : r/artificial

AlphaZero and MuZero - Google DeepMind
Recomendado para você
-
 Stockfish (chess) - Wikipedia17 novembro 2024
Stockfish (chess) - Wikipedia17 novembro 2024 -
chess-alpha-zero/readme.md at master · Zeta36/chess-alpha-zero · GitHub17 novembro 2024
-
Has the Alpha Zero chess program been made to play the Evans Gambit against itself, in an attempt to discover whether that gambit, with best play, is theoretically sound or whether White17 novembro 2024
-
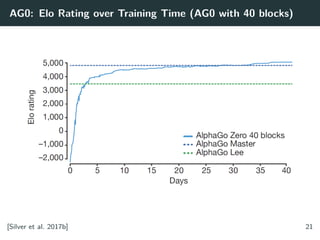 AlphaZero17 novembro 2024
AlphaZero17 novembro 2024 -
 engines - How is Alpha Zero more human? - Chess Stack Exchange17 novembro 2024
engines - How is Alpha Zero more human? - Chess Stack Exchange17 novembro 2024 -
 8 Grandmasters Together Play against Alfazero (4000 elo), chess strategy, Alphazero vs GM17 novembro 2024
8 Grandmasters Together Play against Alfazero (4000 elo), chess strategy, Alphazero vs GM17 novembro 2024 -
 Better than Alphazero !! 4000 Elo Performance of Alfazero17 novembro 2024
Better than Alphazero !! 4000 Elo Performance of Alfazero17 novembro 2024 -
 5000 ELO CHESS BRILLIANCE: Stockfish Vs AlphaZero17 novembro 2024
5000 ELO CHESS BRILLIANCE: Stockfish Vs AlphaZero17 novembro 2024 -
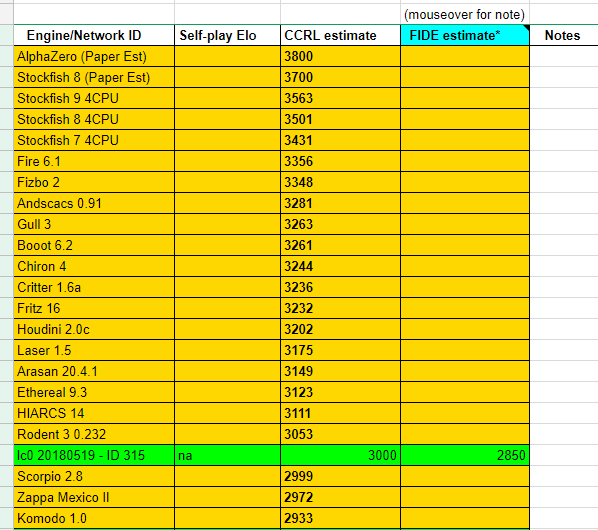 Leela Zero( A Neural Network engine similar to Alpha Zero) - Chess Forums - Page 1517 novembro 2024
Leela Zero( A Neural Network engine similar to Alpha Zero) - Chess Forums - Page 1517 novembro 2024 -
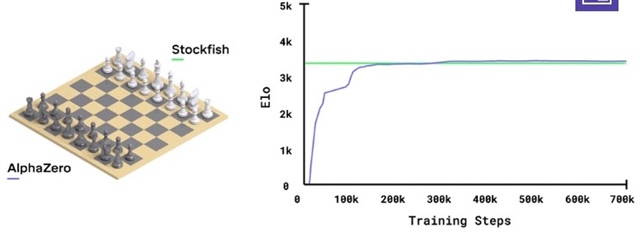 AlphaZero: Four Hours to World Class from a Standing Start - Breakfast Bytes - Cadence Blogs - Cadence Community17 novembro 2024
AlphaZero: Four Hours to World Class from a Standing Start - Breakfast Bytes - Cadence Blogs - Cadence Community17 novembro 2024
você pode gostar
-
 Roblox Shirt ID Codes List - February 2023 « HDG17 novembro 2024
Roblox Shirt ID Codes List - February 2023 « HDG17 novembro 2024 -
O próximo Jogo Grátis da Epic Games Store é misterioso17 novembro 2024
-
 Zatch Bell! Side Story: Friends Manga17 novembro 2024
Zatch Bell! Side Story: Friends Manga17 novembro 2024 -
 Eensy Weensy / Itsy Bitsy Spider in Illustrated Song17 novembro 2024
Eensy Weensy / Itsy Bitsy Spider in Illustrated Song17 novembro 2024 -
 Shooter Bubble - Sea World by 鑫 王17 novembro 2024
Shooter Bubble - Sea World by 鑫 王17 novembro 2024 -
Quebra-cabeça personalizado 60pç17 novembro 2024
-
 Lembra dele? Gordinho do meme da risada perde peso e vira funkeiro17 novembro 2024
Lembra dele? Gordinho do meme da risada perde peso e vira funkeiro17 novembro 2024 -
 Komodo Dragons — City of Albuquerque17 novembro 2024
Komodo Dragons — City of Albuquerque17 novembro 2024 -
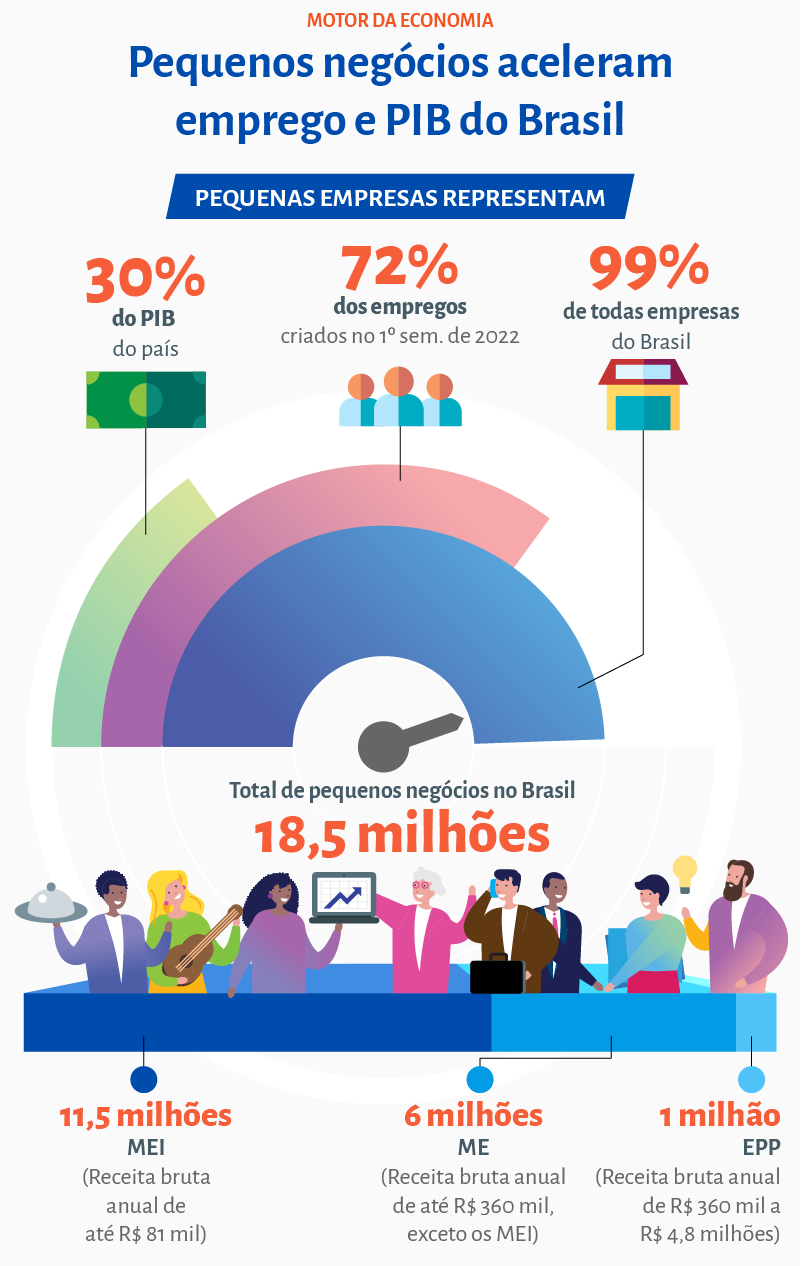 Dia da Micro e Pequena Empresa evidencia a importância dos empreendedores para o Brasil17 novembro 2024
Dia da Micro e Pequena Empresa evidencia a importância dos empreendedores para o Brasil17 novembro 2024 -
 Deus super Saiyajin blue ou red? Qual é mais forte?17 novembro 2024
Deus super Saiyajin blue ou red? Qual é mais forte?17 novembro 2024